TL;DR: We present MultiWorld, a
scalable multi-agent multi-view video world model that generates action-controllable,
multi-view consistent videos for both multi-player games and multi-robot manipulation.
Abstract
Video world models have achieved remarkable success in simulating environment dynamics,
yet most existing approaches are limited to single-agent scenarios, failing to capture
complex interactions inherent in real-world multi-agent systems. We present MultiWorld,
a unified framework for multi-agent multi-view world modeling that enables accurate
control of multiple agents while maintaining multi-view consistency.
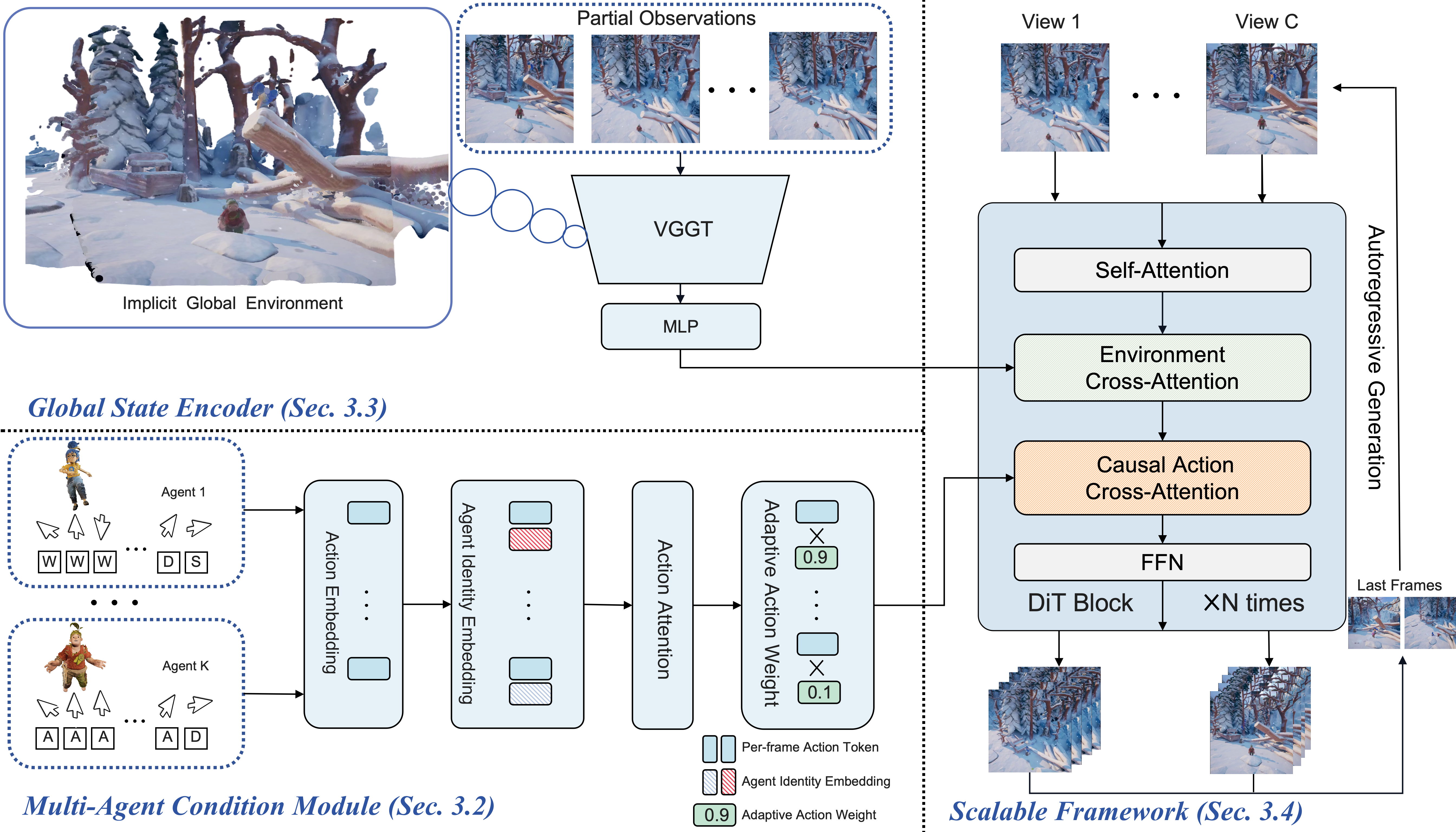
We introduce the Multi-Agent Condition Module (MACM) to achieve precise multi-agent
controllability, and Global State Encoder (GSE) to ensure coherent observations across
different views. MultiWorld allows the number of agents and views to be flexibly scaled.
Meanwhile, MultiWorld synthesizes different views in parallel, enabling high efficiency
and scalability across multiple views.
Experiments on multi-player game environments and multi-robot manipulation tasks demonstrate
that MultiWorld outperforms baselines in video fidelity, action following ability, and multi-view consistency.
Method
Multi-Agent Condition Module
Agent Identity Embedding (AIE): Uses Rotary Position Embedding to inject distinct agent identities into action tokens, resolving identity ambiguity.
Adaptive Action Weighting (AAW): Dynamically prioritizes active agents over static ones to focus on dynamic changes.
Global State Encoder
Employs pretrained VGGT for 3D-aware feature extraction from multi-view observations.
Compresses observations into a compact global representation via cross-attention, enabling consistent multi-view synthesis.
Scalability
K
Variable Agents
AIE naturally extends to any number of agents
C
Variable Views
GSE handles arbitrary camera counts
1.5×
Speedup
Parallel view generation
Results
Multi-Player Video Game (It Takes Two)
Method
FVD ↓
LPIPS ↓
SSIM ↑
PSNR ↑
Action ↑
RPE ↓
Standard
245
0.36
0.50
17.48
88.4
0.75
Concat-View
215
0.36
0.49
17.54
89.1
0.74
COMBO
207
0.34
0.51
17.82
89.3
0.72
MultiWorld
179
0.35
0.51
17.72
89.8
0.67
Multi-Robot Manipulation (RoboFactory)
Method
FVD ↓
LPIPS ↓
SSIM ↑
PSNR ↑
Action ↑
RPE ↓
Standard
100
0.07
0.90
26.39
88.2
1.60
Concat-View*
106
0.06
0.90
27.44
92.0
0.82
COMBO
99
0.08
0.90
26.49
88.5
1.54
MultiWorld
96
0.07
0.90
26.60
88.7
1.52
*Concat-View trained on two camera views only. Bold = best, blue = second best.
Generated Gameplay Gallery
AI-generated multi-player gameplay videos from the It Takes Two dataset.
Robot Manipulation Gallery
Multi-robot manipulation tasks from RoboFactory dataset.
Two Robots Stack Cube - Success Trajectory #1
Two Robots Stack Cube - Success Trajectory #2
Two Robots Stack Cube - Success Trajectory #3
Three Robots Stack Cube - Failure Trajectory #1
Three Robots Stack Cube - Failure Trajectory #2
Datasets
It Takes Two
100+ hours of real-player gameplay
60 FPS with synchronized keyboard/mouse actions
Dual-agent with distinct viewpoints
Resolution: 480x960
RoboFactory
4 multi-robot manipulation tasks
2-4 agents with variable viewpoints
1,000 success episodes and 2,000 failure episodes per task
Resolution: 256×320
Citation
@article{wu2025multiworld,
title ={MultiWorld: Scalable Multi-Agent Multi-View Video World Models},
author ={Wu, Haoyu and Yu, Jiwen and Zou, Yingtian and Liu, Xihui},
journal ={arXiv preprint arXiv:2604.18564},
year ={2025}
}